When generating text using the GPT-2 Large model, we found that both the method of generation, and text prompt used, have a statistically significant effect on on the output produced. In four out of six trials we found that the Nucleus Sampling method proposed by Holtzman, et all1Holtzman, Buys, Du, Forbes, Choi. (2020). The Curious Case of Natural Text Degeneration. ICLR 2020. Retrieved February 1, 2020, from https://arxiv.org/pdf/1904.09751.pdf, (aka Top-P)produced output that was significantly more humanlike than other methods. We also found that some troublesome prompts, such as the first sentence of the Bible, consistently produce outputs that seem relatively unaffected by the choice of generation method.
Introduction
Generative models such as GPT-2 are capable of creating text output of impressive quality, sometimes indistinguishable from that of humans.
[…] Dr. Jorge Pérez, an evolutionary biologist from the University of La Paz, and several companions, were exploring the Andes Mountains when they found a small valley, with no other animals or humans. Pérez noticed that the valley had what appeared to be a natural fountain, surrounded by two peaks of rock and silver snow.
Pérez and the others then ventured further into the valley. “By the time we reached the top of one peak, the water looked blue, with some crystals on top,” said Pérez. […]
Using GPT-2 to output something we can read requires a specific text generation method, a programmatically defined strategy for selecting the next tokens in each sequence. We are thus faced with a question: which generation method yields the best output from this model?
In the 2020 paper The Curious Case of Natural Text Degeneration1Holtzman, Buys, Du, Forbes, Choi. (2020). The Curious Case of Natural Text Degeneration. ICLR 2020. Retrieved February 1, 2020, from https://arxiv.org/pdf/1904.09751.pdf, Holtzman, et all, introduced Nucleus Sampling, also known as Top-P. The authors claim this new text generation method produces better, more humanlike output, when measured in terms of perplexity and HUSE.
All of our generated texts were created by the GPT-2 Large model, the same model used by Holtzman, et all1Holtzman, Buys, Du, Forbes, Choi. (2020). The Curious Case of Natural Text Degeneration. ICLR 2020. Retrieved February 1, 2020, from https://arxiv.org/pdf/1904.09751.pdf. This model was released in 2019, includes 774 million trained parameters, a vocabulary size of 50,257, and input sequences of 1,024 consecutive tokens.
Our Experiment
We began with six pieces of human generated text, including the first paragraph of “A Tale of Two Cities”, passages from Douglas Adams, Dr. Seuss, and the Bible, a randomly selected CNN article, and a randomly selected Reddit comment. These samples were roughly the same size in terms of length, and selected to represent a wide range of natural language.
We used the first few words of each human text to serve as our prompts:
It was the best of times, it was the worst of times, it was
“Forty-two!” yelled Loonquawl. “Is that all you’ve got
At the far end of town where the Grickle-grass grows
In the beginning God created the heaven and the earth.
Having arrived in China as the most successful
Yes! This! I wanted to say that the thing I wanted
For each of these six prompts, we generated ten texts using each of the following five methods:
Beam Search num_beams = 15 early_stopping = True
Sampling do_sample = True top_k = 0
Temperature do_sample = True top_k = 0 temperature=0.7
This resulted in 300 generated texts (10 per prompt per method), each with a max length of 250 tokens. For each of these generated texts, we calculated the following three metrics:
Total Repetitions How repetitive is a given text? We have defined this metric with the Python function calculate_repetitions. Our function ignores capitalization and punctuation, and breaks input into overlapping 3grams based on word boundaries.
Perplexity How likely is it that the GPT-2 Large model would generate a given text? We have defined this metric with the Python function calculate_perplexity. This is the exponentiated average negative log-likelihood of each generated text.
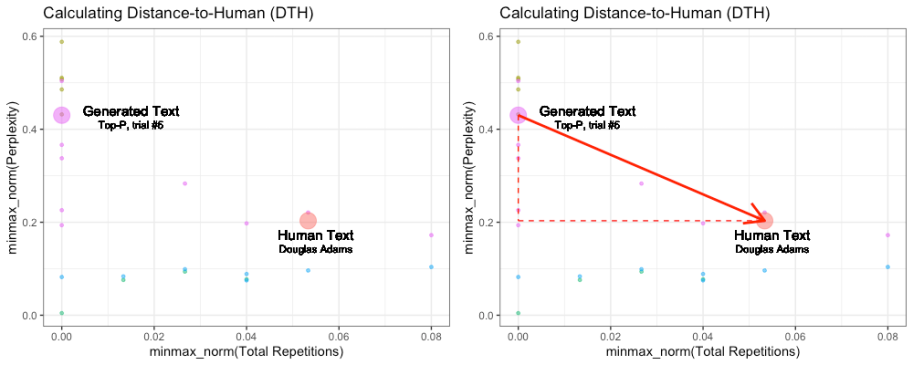
Distance-to-Human (DTH) How humanlike is a given text? We have defined this metric as the Euclidean Distance between a generated text, and the human sample that shares its prompt, based on total repetitions and perplexity, after first min/max normalizing these scores to all text (generated and human) belonging to the same prompt.
For example, when calculating DTH for Douglas Adams, we first normalized the scores of all 50 texts generated from the prompt “Forty-two!” yelled Loonquawl. “Is that all you’ve got?, plus the original passage from The Hitchhiker’s Guide to the Galaxy.
Our experiment did not include a HUSE analysis due to a lack of resources.
Statistical Analysis
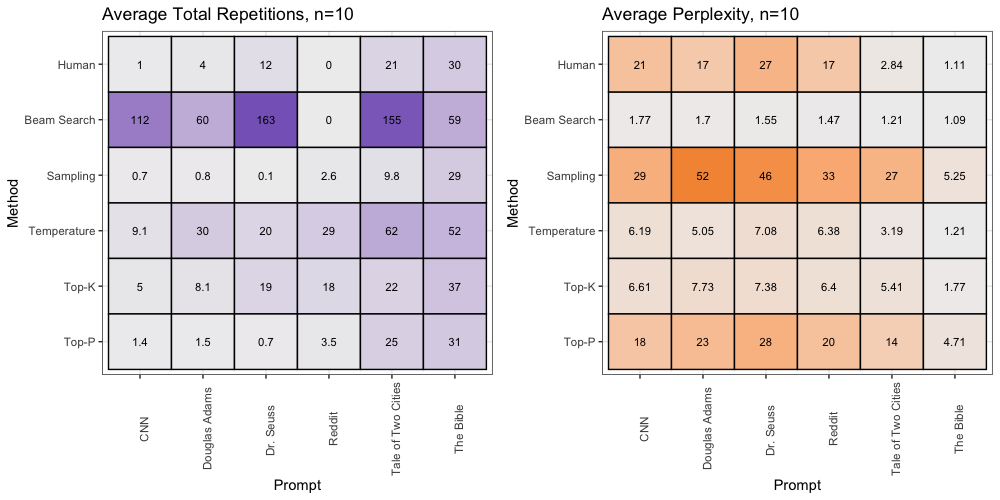
Based on a simple average, we can see a clear interaction between the generation method and prompt used:
Methodology
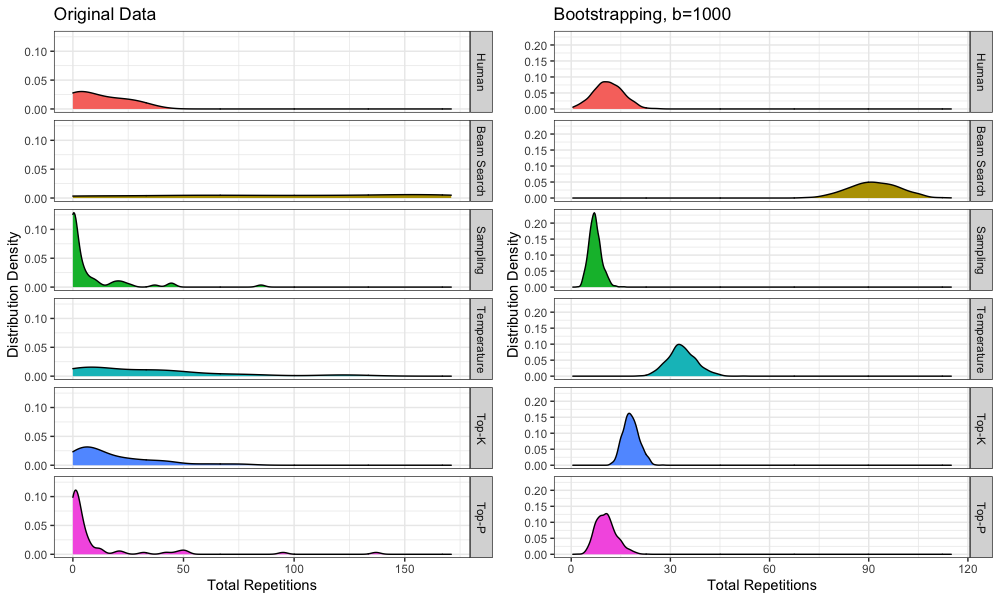
We attempted to measure this interaction via ANOVA analysis, but found evidence of extreme heteroscedasticity due to the abnormal distributions of the above scores. We relied on bootstrapping3James, Witten, Hastie, Tibshirani. (2013). An Introduction to Statistical Learning with Applications in R. pp. 187. instead, using 1,000 iterations of sampling with replacement to calculate the expected means.
We can see the effect of this bootstrapping below:
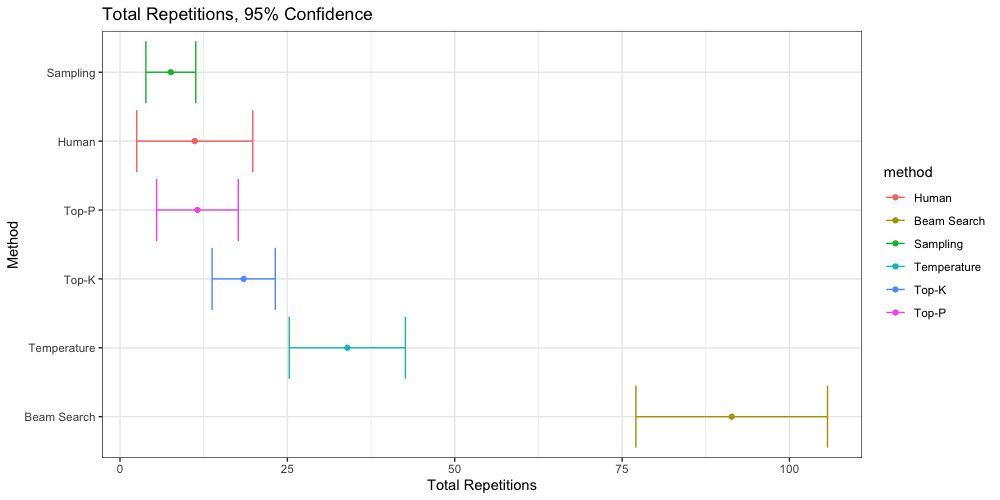
This allows us to calculate 95% confidence intervals, visualized below.
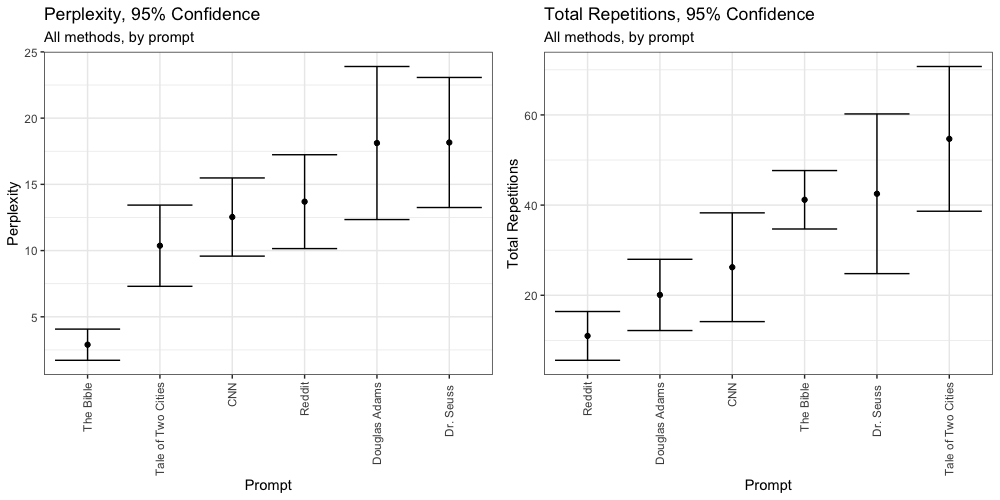
Total Repetitions
We can say with 95% confidence that texts generated via Beam Search are significantly more repetitive than any other method. We see no significant differences between Top-P, Top-K, Sampling, or the human generated texts. All four are significantly less repetitive than Temperature.
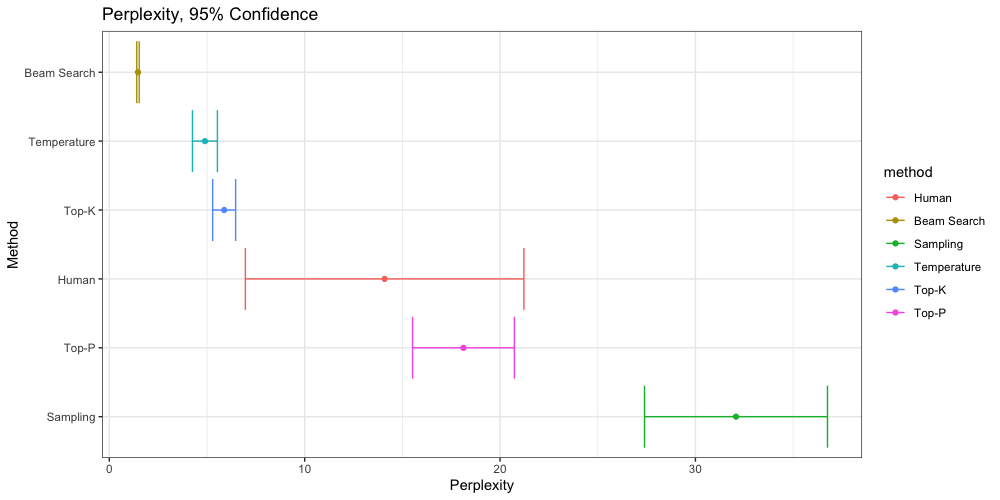
Perplexity
We can say with 95% confidence that Beam Search is significantly less perplexing than all other methods, and Sampling is significantly more perplexing than all other methods. There is no significant difference between Temperature or Top-K in terms of perplexity, but both are significantly less perplexing than our samples of human generated text.
We see that our six samples of human text (red) offer a wide range of perplexity. Top-P is the only method which falls within this range with 95% confidence. We also find that Top-P generates output with significantly less perplexity than Sampling, and significantly more perplexity than all other non-human methods.
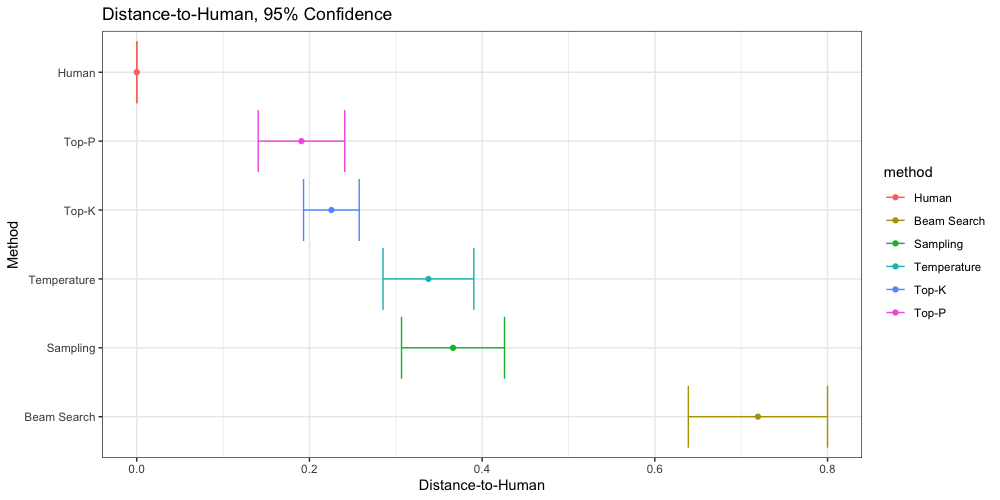
Distance-to-Human (DTH)
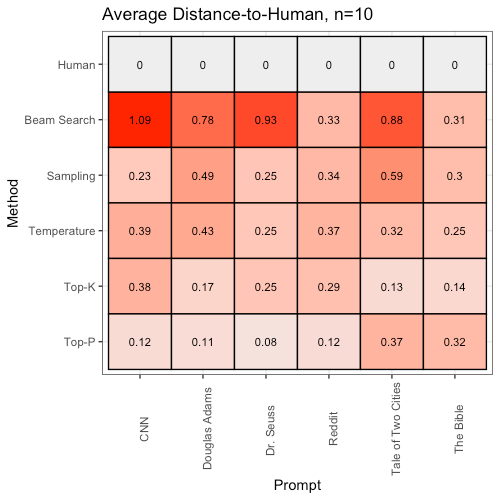
Once again, based on a simple average, we can see a clear interaction between the generation method and prompt used:
We find Top-P has a lower DTH (is more humanlike) than any other non-human method when given four out of these six prompts. However, when prompted with “It was the best of times, it was the worst of times, it was” from “Tale of Two Cities”, Top-P (0.37) loses to both Temperature (0.32) and Top-K (0.13). When prompted with “In the beginning God created the heaven and the earth.” from the Bible, Top-P (0.32) loses to all other methods.
We can say with 95% confidence that both Top-P and Top-K have significantly lower DTH scores than any other non-human method, regardless of the prompt used to generate the text. When considering all six prompts, we do not find any significant difference between Top-P and Top-K.
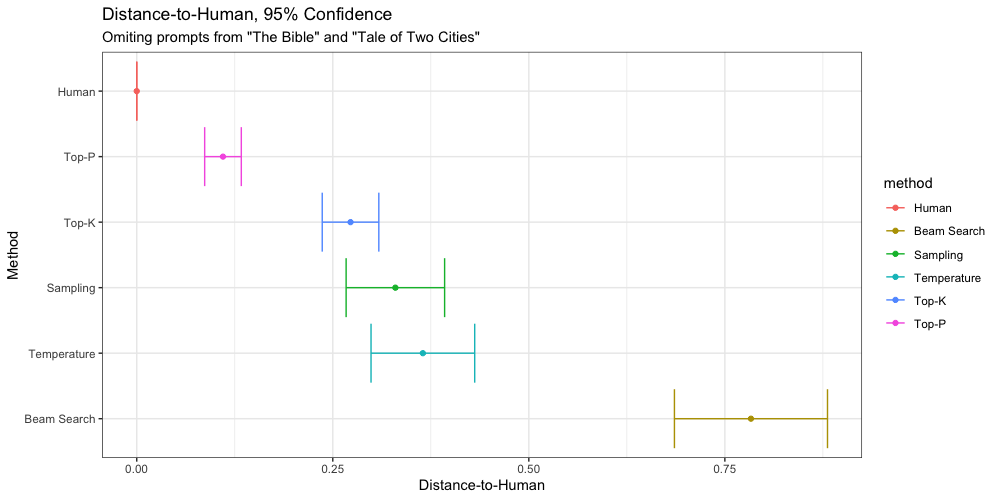
If we ignore the output of our two troublesome prompts, we find with 95% confidence that there is a statistically significant difference between Top-P and Top-K. Here we find Top-P has significantly lower DTH scores than any other non-human method, including Top-K. This is also evidence that the prompt itself has a significant impact on the output.
Effect of Prompt
The variance in our measured output scores can not be explained by the generation method alone. The prompt also has an effect. Below we see the result of the same bootstrap analysis when grouped by prompt, rather than generation method:
We can say with 95% confidence that generated text based on the prompt “In the beginning God created the heaven and the earth.” from the Bible has significantly less perplexity than text generated from any other prompt, regardless of the generation method used.
Troublesome Prompts
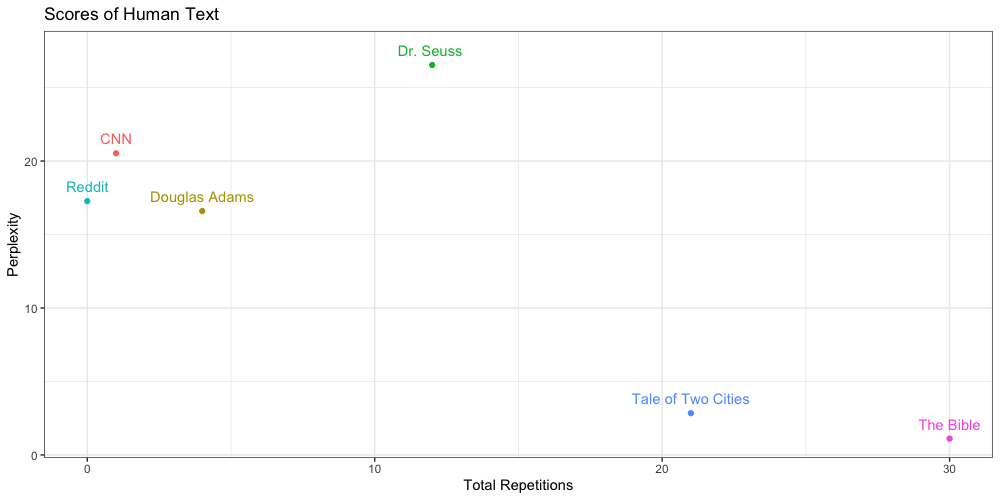
Below are the scores of the human generated texts:
We find that the sources of our two troublesome prompts (“Tale of Two Cities” and “The Bible”) have the lowest perplexity, and highest repetition, of the human generated texts. This leads to an interesting observation:
Prompt: The Bible
Method: Beam Search
Trial: 1
In the beginning God created the heaven and the earth. And the earth was without form, and void; and darkness was upon the face of the deep. And the Spirit of God moved upon the face of the waters.[…]
Perplexity: 1.08
Total Repetitions: 48
Prompt: The Bible
Method: Top-P, p=0.95
Trial: 1
In the beginning God created the heaven and the earth. And the earth was without form, and void; and darkness was upon the face of the deep. And the Spirit of God moved upon the face of the waters. […]
Perplexity: 1.83
Total Repetitions: 12
Regardless of the generation method used, the Bible prompt consistently yields output that begins by reproducing the same iconic scripture. We see the same effect, to a lesser degree, with “Tale of Two Cities”:
Prompt: Tale of Two Cities
Method: Beam Search
Trial: 1
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair […]
Perplexity: 1.20
Total Repetitions: 156
Prompt: Tale of Two Cities
Method: Top-P, p=0.95
Trial: 1
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair […]
Perplexity: 5.84
Total Repetitions: 50
Levenshtein Similarity
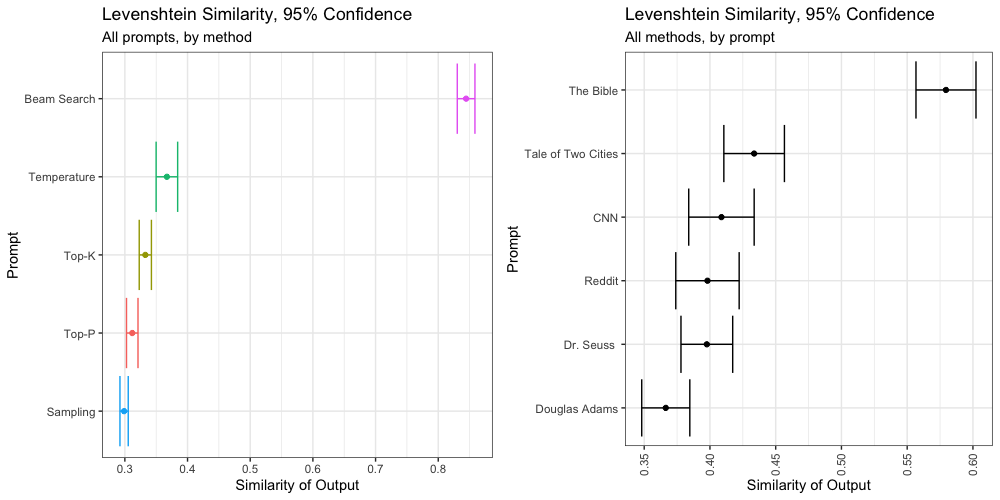
To better illustrate the above observation, we calculated the Levenshtein Similarity of all generated texts. We compared each individual text to the other nine texts generated by the same prompt and method. Then we used the same bootstrapping methodology from above to calculate 95% confidence intervals.
We can say with 95% confidence that outputs from Beam Search, regardless of prompt, are significantly more similar to each other. Likewise we can say with 95% confidence that outputs prompted by the Bible, regardless of generation method, are significantly more similar to each other.
We also see that output based on “Tale of Two Cities” is more similar, but not significantly so. There is enough variety in this output to fool a Levenshtein test, but not enough to fool a human reader.
Conclusion
We find that outputs from the Top-P method have significantly higher perplexity than outputs produced from the Beam Search, Temperature or Top-K methods. However, of the methods tested, only Top-P produced perplexity scores that fell within 95% confidence intervals of the human samples. This supports the claims of Holtzman, et all that Nucleus Sampling [Top-P] obtains closest perplexity to human text (pp. 6)1Holtzman, Buys, Du, Forbes, Choi. (2020). The Curious Case of Natural Text Degeneration. ICLR 2020. Retrieved February 1, 2020, from https://arxiv.org/pdf/1904.09751.pdf.
How can we explain the two troublesome prompts, and GPT-2’s subsequent plagiarism of “The Bible” and “Tale of Two Cities”? We posit that some specific texts are so iconic, repeated so often in the text GPT-2 was trained on, that the likelihood of these sequences simply overwhelms the effects of any generation methods tested. We suspect other such troublesome prompts exist, and will continue to exist in future models, for the same reason.
We find that outputs from Beam Search are significantly less perplexing, more repetitive, and more similar to each other, than any other method tested. Considering Beam Search’s propensity to find the most likely outputs (similar to a “greedy” method) this makes sense. This also explains why these outputs are the least humanlike.
We also find that outputs from our Sampling method are significantly more perplexing than any other method, and this also makes sense. Here we are sampling from the entire probability distribution, including a long right tail of increasingly unlikely options.
When it comes to Distance-to-Human (DTH), we acknowledge this metric is far inferior to metrics such as HUSE which involve human evaluations of generated texts. Accepting the limitations of this experiment, we remain 95% confident that outputs from Top-P and Top-K are more humanlike than any other generation methods tested, regardless of prompt given.
We suspect that a larger experiment, using these same metrics, but testing a wider variety of prompts, would confirm that output from Top-P is significantly more humanlike than that of Top-K.
References
1
Holtzman, Buys, Du, Forbes, Choi. (2020). The Curious Case of Natural Text Degeneration. ICLR 2020. Retrieved February 1, 2020, from https://arxiv.org/pdf/1904.09751.pdf