
Introduction
Given some text from an unknown author, could you determine whether it was written by a human, or generated by a machine?
This was the question posed by Alan Turing’s “imitation game”, back in his 1950 paper Computing Machinery and Intelligence. Fans of science fiction may remember it by its more colloquial name: the Turing test. Turing argued that any AI author that was able to fool a human could be considered a legitimate “machine that can think”.

Using AI to generate text with human-level intelligence has a long and rich history, and we’ve made amazing progress in these past 7 decades. In 2020, OpenAI made waves by releasing the 3rd version of the Generative Pre-trained Transformer (GPT-3). Both machine learning professionals, and the general public, have been awestruck by the humanlike quality of the text it generates. GPT-3 has inspired countless media reports, the dedicated /r/GPT3 subreddit, and more recently, the December 31, 2021 episode of This American Life featured a segment co-written by Vauhini Vara and GPT-3. Is the age of “machines that can think” finally upon us?
This article serves to separate the hype from the reality. This article also serves as a full crash course in neural text generation. Below we will review various methods of generating text with GPT-2 (the “little brother” of GPT-3), including Beam Search, Top-K and Top-P sampling. We will also review some key metrics of generated text, including perplexity and repetition, and try to get a more intuitive sense of these measures.
Those eager to jump into code can skip ahead to this excellent colab written by Patrick von Platen at HuggingFace.
Meet the Model
The 2nd version of the Generative Pre-trained Transformer (GPT-2) was first proposed in the 2018 paper Language Models are Unsupervised Multitask Learners, and later released in 2019. As the model card explains:
The OpenAI team wanted to train this model on a corpus as large as possible. To build it, they scraped all the web pages from outbound links on Reddit which received at least 3 karma […] The texts are tokenized using a […] vocabulary size of 50,257. The inputs are sequences of 1024 consecutive tokens […] The larger model was trained on 256 cloud TPU v3 cores.
When training supervised machine learning models, we use labels, the correct answers, to teach the model what it is looking for. In this situation, we want our model to write its own text. There is no correct answer to label; here we are unsupervised. The best we can do is look at probabilities.
For example, what are the relative likelihoods of the following sequences?
- peanut butter and jelly sandwich
- peanut butter and sardine sandwich
- peanut butter and dancing sandwich
This is essentially what the GPT-2 model is trying to learn during training. While grinding through a massive corpus of training text, it builds a network of weights (parameters) that define these conditional probabilities based on the larger contexts of surrounding text.
Of course, this is math, not magic. But in order to do mathematical operations on words, we must first turn them into numbers. How do we do that?
What began with one hot encoding of specific tokens has evolved into multi-dimensional embeddings (vectors) that abstract the meaning of language from words, sentences, and full paragraphs. Instead of representing specific tokens as binary 0’s and 1’s, text is encoded into embeddings (vectors) with many dimensions (numbers). We can use cosine similarity to compare any two embeddings (vectors), no matter how abstract they might become.
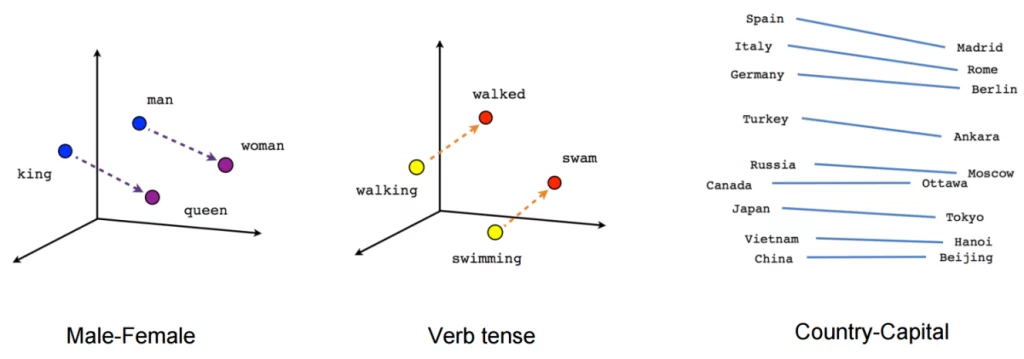
Embeddings are very powerful, but we still need a model architecture capable of learning these advanced embeddings and context-based probabilities.
Considering text is just a sequence of tokens, RNNs seemed like an obvious choice early on. Later research paired RNN models with CNNs to better extract sequence-independent context from language. The 2017 paper Attention Is All You Need proposed replacing the RNN altogether with a new Attention Unit. This was soon paired with embedded Encoders and Decoders in order to produce the modern Transformer architecture (the T in GPT-2).
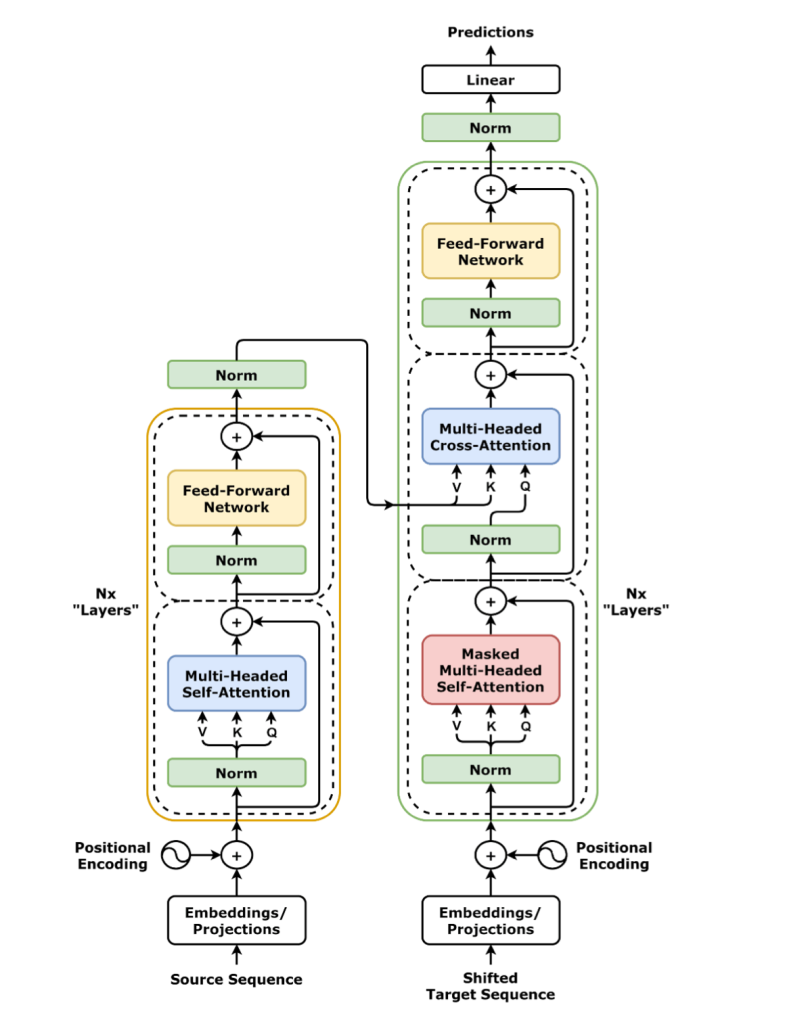
Figure 10.13 – The Transformer (norm-first)
Deep Learning with PyTorch, Godoy, pg 942
If the above illustration leaves you scratching your head, I will refer you to Godoy’s excellent book for more details. Generally speaking, the better you understand a model, the better you will understand its output. That said, this article focuses on using the GPT-2 model that is already here; further details on how they made it are not required to follow the rest of this article.
Generating Text
Now that we’ve got this super cool model, how do we use it? HuggingFace has already provided sample code that can be run directly through your web browser via this excellent Google colab. You can also find the full output of our GPT-2 generated texts here.
One small change: for the samples below I used the “gpt2-large” version, which includes a full 774 million parameters (weights).
# using the "gpt-2 large" version
tokenizer = GPT2Tokenizer.from_pretrained("gpt2-large")
model = TFGPT2LMHeadModel.from_pretrained("gpt2-large", pad_token_id=tokenizer.eos_token_id)
Those 774 million parameters in our fancy-pants GPT-2 model can seem overwhelming at first. But underneath all these elaborate tensors and embeddings, we are left with an extension of the “peanut butter and jelly” question from above. As it turns out, no matter which method we use to generate our text, it all comes down to conditional probabilities.
Beam Search
The below illustration may look familiar to those of you who have worked with Markov Chains before:
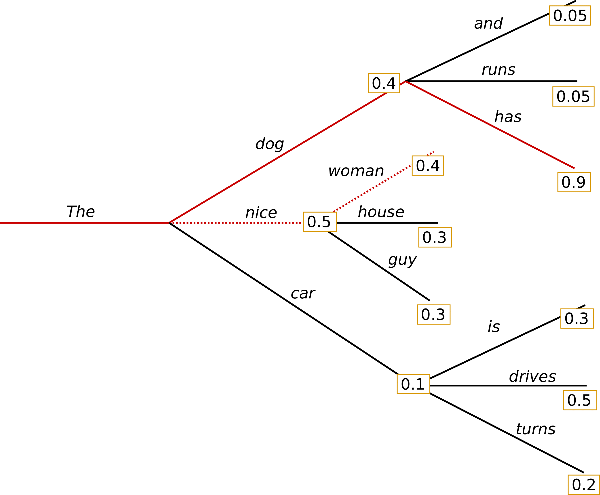
In this example, the word “The” has a 40% chance of being followed by the word “dog”, a 50% chance of being followed by the word “nice”, and a 10% chance of being followed by the word “car”.
In our model, these probabilities are derived from the specific text GPT-2 was trained on: 40GB of texts scraped from websites shared on Reddit.
Beam Search uses conditional probabilities to explore different branches (beams). In the above example, “The dog (40%) has (90%)” has a (0.4 x 0.9) 36% probability, while “The dog (40%) runs (5%)” has a (0.4 x 0.05) 2% probability. The terminal nodes with the highest conditional probabilities win.
Here the model tracked 15 beams, and returned the best 10:
# set model parameters
beam_outputs = model.generate(
input_ids,
num_return_sequences=10,
max_length=250,
num_beams=15,
early_stopping=True)
Here is a sample output (text prompt in blue):
At the far end of town where the Grickle-grass grows there is a small pond. In the middle of the pond there is a small pond. In the middle of the pond there is a small pond. In the middle of the pond there is a pond. In the middle of the pond there is a pond. In the middle of the pond there is a pond. In the middle of the pond there is a pond […]
As we see above, picking the most probable sequence is not always the best. Our model gets stuck in a loop almost immediately. Repetition like this is a common problem with neural generated text.
Sampling
Imagine we are generating the next token in the sequence:
- peanut butter and ?????
At each step in our generated strings, we can find a probability distribution of potential next tokens, based on the context of the prompt and the text the model has already generated.
Consider the following example:
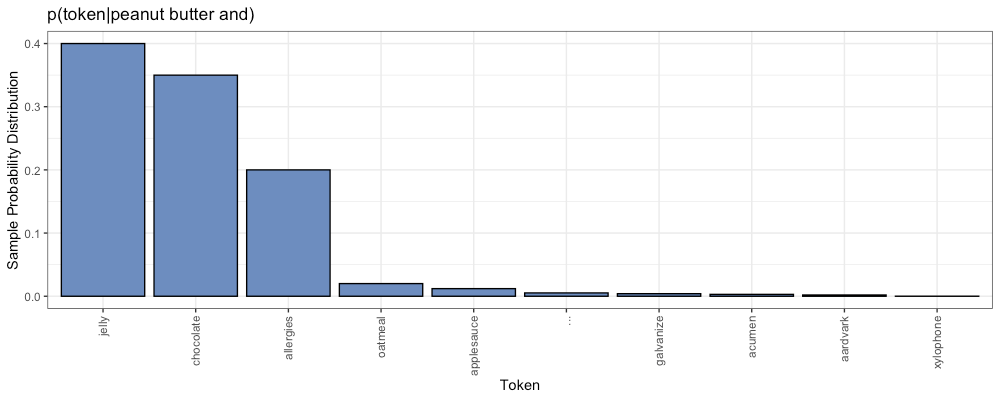
In the above distribution we see some options with high probabilities (left):
- peanut butter and jelly
- peanut butter and chocolate
We also find options with very low probabilities (right tail):
- peanut butter and aardvark
- peanut butter and xylophone
Sampling randomly selects the next token according to this probability distribution. The model will probably choose “jelly” or “chocolate”. However, there is also a small chance our model will choose “xylophone” instead.
# set model parameters
sampling_outputs = model.generate(
input_ids,
num_return_sequences=10,
max_length=250,
do_sample=True,
top_k=0)
Here is a sample output (text prompt in blue):
At the far end of town where the Grickle-grass grows iced over, an 18-wheeler of Steelers had gone by him about 12 miles earlier, laden with barrels of dark tarol, a mildly poisonous natural gas produced from natural deposits in the surrounding mountains. CPS, his longtime car dealer, had come up with another solution to make it through the stretch of cracked pavement. It consisted of hoists and cables draped over the tires, attached at their hubs only by braided wire. Most notably, each tire had been replaced with a radiating axolotl from Florida with an opening hood made from McMuffin’s frying pan. […]
It appears we’ve solved the problem of repetition, but now we see a new problem: this output is weird. Consider another output, generated using the same method (text prompt in blue):
“Forty-two!” yelled Loonquawl. “Is that all you’ve got?”
“F[word], I dont care anymore. Turns out my boyz is sucka. They like their Internet under driveways. FOH!” The entire street erupted into screams and chuckles. Nobody was even willing to reach out to touch them because everyone knew that Loonquawl heroically jumped off of the roof and O’Brien screamed that Loonquawl had hit them in the august chest and everyone screamed back. They had a good laugh.
By the time Loonquawl was about to return my noose, I smelled gunpowder and pointed it straight at his vest and shouted, “Mentĕons for McDonalds!!!” […]
This one makes even less sense. Some parts are pretty perplexing. What is “Internet under driveways”? What is an “august chest”? How do you point gunpowder at somebody? The output feels a bit too random now.
The issue lies in the long right tail of increasingly improbable options. Sooner or later the model is going to pick some very unlikely tokens, and this will result in some very weird output.
Temperature
The purpose of Temperature is to adjust the above probability distribution, increasing the probabilities of the most likely words. We hope this will result in making better token selections. Mathematically:
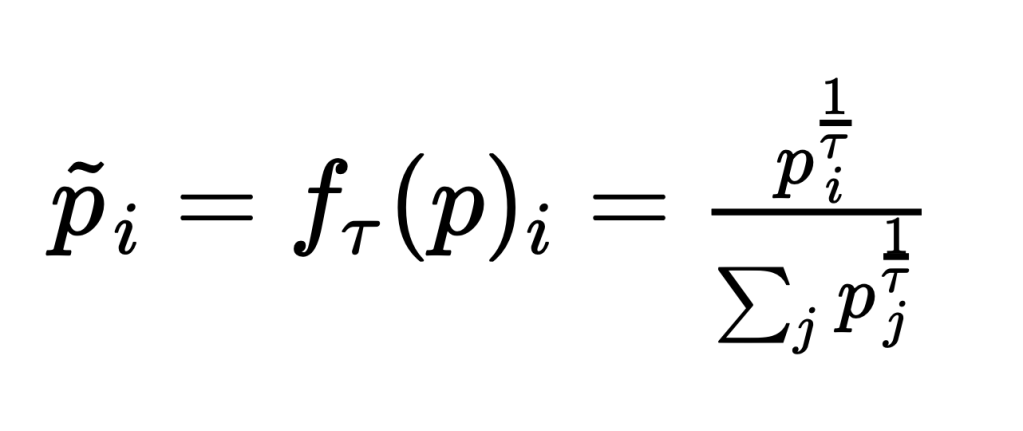
We adjust Temperature via the parameter 𝜏. As 𝜏 approaches 0, this results in an argmax function. We will always pick the most likely token, Greedy output, which is similar to Beam Search. As 𝜏 approaches 1, the effect of Temperature disappears, and we are back to plain Sampling.
Here the model used 𝜏 = 0.7:
# set model parameters
temperature_outputs = model.generate(
input_ids,
num_return_sequences=10,
max_length=250,
do_sample=True,
top_k=0,
temperature=0.7)
Here is a sample output (text prompt in blue):
Having arrived in China as the most successful new breed of dog in history, the short-haired, blond-and-blue-eyed, big-eyed, blue-eyed and white-eyed Pekingese are now seen as the most popular breed in China, with more than 110 million dogs worldwide.
The Chinese government still prohibits dogs from owning cats, and the Pekingese is one of the few breeds banned from owning birds. But the breed has recently been given a second chance—the biggest of them all, the Pekingese, has been deemed an “extended family pet” by the government.
“We have been able to give them a second chance because we have maintained their definition of family pet,” says Jiang Yao, director of the Beijing Pekingese Association.
To qualify as an extended family pet, the dog must be of the same breed and size as the owner. The breeder also must have lived in the same household for 12 consecutive years, and the dog must have a mother-cousin relationship with the owner.
“It is hard to find a breed that is accepted by the government, so I think it is a good thing that this breed will be allowed to start
I have to ask: how many dogs owned cats and birds in China before the ban? This text still contains some weirdness, but overall, the generated text is starting to look pretty good. Notice that the passage focuses on the Pekingese all the way through.
Top-K
Top-K is another approach to the issue of long right tails in our probability distributions. Here, instead of applying some fancy-pants math formula, we just ignore everything after the kth position. For example, k=5:
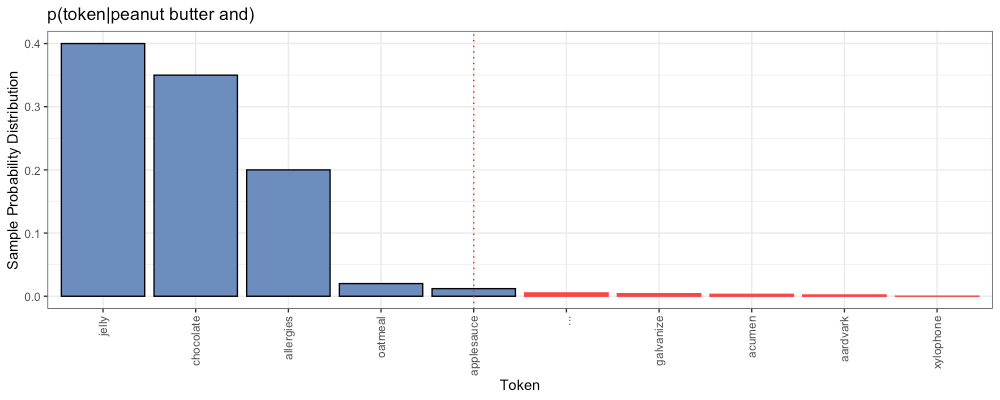
In this example, our model will only choose from the 5 most probable options, “jelly”, “chocolate”, “allergies”, “oatmeal” and “applesauce”. Everything further to the right (no matter how long the tail) is simply ignored. We scale the probabilities of the top k so they sum to 100%, and maintain their same relative proportions. Then we choose accordingly.
Here the model used k = 10:
# set model parameters
top_k_outputs = model.generate(
input_ids,
num_return_sequences=10,
max_length=250,
do_sample=True,
top_k=10)
Here is a sample output (text prompt in blue):
“Forty-two!” yelled Loonquawl. “Is that all you’ve got!” The two other men stood and watched the man, then turned to their leader.
“I’m ready,” he replied. “I’m ready.”
The four of them took their bows and began to approach the tent. As the last soldier was about to step inside, the tent door opened to reveal a woman in a red dress. She had a large, red hat over her head that was tied at her neck with a ribbon. Her face was covered by a hood that was tied with a ribbon at her forehead. The woman’s dress was red from the top down, and it was cut in the same style as the other soldiers. The hat covering her head was pulled off her head by a man in red, and then was replaced by a red scarf. The man in red pulled off the red scarf and threw it to the ground. She turned around and stared at her opponent, who was now staring right back at them.
The woman in red raised her arms and began to wave her arms around. Loonquawl was surprised at the sudden change in her demeanor. She had not expected
The above is still a little rough, but I think a human editor could clean that up into something that makes sense.
Of course, the output will vary greatly depending on which value of k you choose. If k=1, we will always pick the most likely token, Greedy output, which is similar to Beam Search. As k approaches infinity, eventually it includes all tokens, and we are back to plain Sampling again.
Top-P
Top-P is yet another approach to the issue of long right tails in our probability distributions. Here, instead cutting off after a certain number of tokens (k), we cut off after a certain abount of cumulative probability (p).
For example, p=0.95:
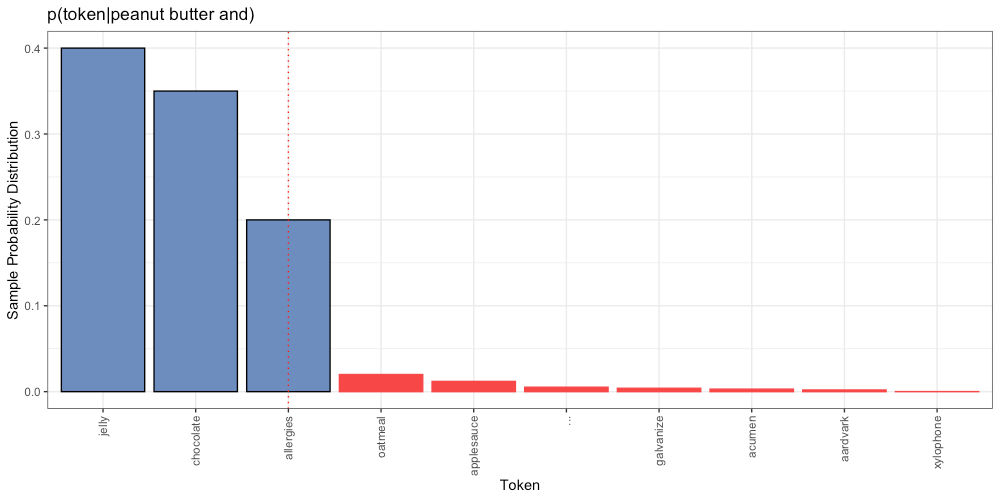
In the above example, there is a 40% chance the next token is “jelly”, a 35% chance the next token is “chocolate”, and a 20% chance the next token is “allergies”. Combined, there is a 95% probability that the next token is one of these three. As with Top-K, we scale the probabilities of the surviving tokens, and choose accordingly.
Here the model used p = 0.95:
# set model parameters
top_p_outputs = model.generate(
input_ids,
num_return_sequences=10,
max_length=250,
do_sample=True,
top_p=0.95,
top_k=0)
Here is a sample output (text prompt in blue):
At the far end of town where the Grickle-grass grows is Leland’s Deli, where people stop by to sell their own crack pipes and old chocolates. The front door is a little tacky but there’s no plaque that remembers the store’s founder either. It belongs to the fifties.
Where Leland’s Deli stands is behind a shed in the backyard. The smog in the background is the last of the west-bank fog, brought in for that very reason.
The story of Leland’s Deli, where people stop to buy drinks, is in the Behind The Hustle review by Dr. Lou Wu.
Look up at your nearest well-trafficked street and you’ll notice this neighborhood is surrounded by buildings, dense with buildings. There’s a abandoned car dealership to the northeast, a small school to the southwest, a highway near the garage, a ranch and a the old Leland’s headquarters beyond them.
Concrete between this street and Rock Springs Boulevard is the Bell and Howell Cook / Rancho San Jose / Franklin & Fernender Company. Despite this, no one from the Bell &
It seems our model is now writing a surreal novel about a dystopian neighborhood where the locals meet to sell their crack pipes and old chocolates. Does it make sense? That’s a tough question. Does Finnegan’s Wake make sense? Does an objective answer exist?
This much I know for sure: “the Behind The Hustle review by Dr. Lou Wu” is some excellent wordplay, and appears to be an original creation by GPT-2.
Measuring Generated Text
Manually reading through hundreds of generated texts is a slow and surreal experience. We need some objective measures to consider.
Total Repetitions
How repetitive is the output? Although a simple question, there are a lot of nuances to consider when defining this metric. Do we look in terms of words, or individual characters? Do we consider punctuation or capitalization differences? What size ngrams count as a repetition? There are no universally agreed upon rules here. Different methods will yield different counts.
We have defined this metric with a simple Python function calculate_repetitions (available as a colab here). Our function ignores capitalization and punctuation, and breaks input into 3grams based on word boundaries. For example:
The 3gram “there was a” is repeated two times:
The 3gram “was a man” is repeated once:
The 3gram “and there was” is repeated once:
We find 4 total repetitions in this sample text.
Perplexity
Mathematically speaking: perplexity is defined as the exponentiated average negative log-likelihood of a sequence.
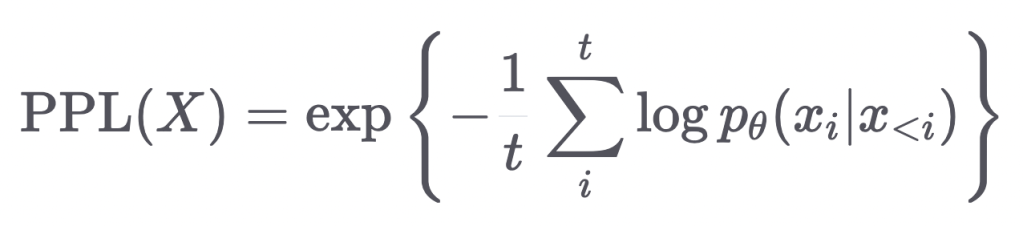
The following animation by HuggingFace helps demystify it:

Put simply: how likely is it that our model returned this output? This depends on the specific probability distributions of the model. Perplexity of fixed-length models (colab) includes a working example with GPT-2, provided by the good folks at HuggingFace. This is what we have used for calculating the perplexity scores shown here.
Another nuance to consider: the GPT-2 model can only handle 1,024 consecutive tokens at a time. Our outputs here were small enough to avoid this limitation, but when working with longer text outputs, we must rely on the sliding window strategy as visualized below:
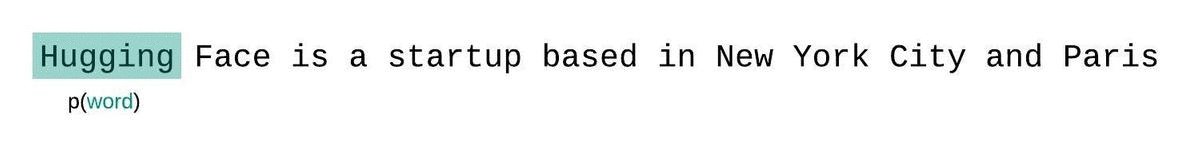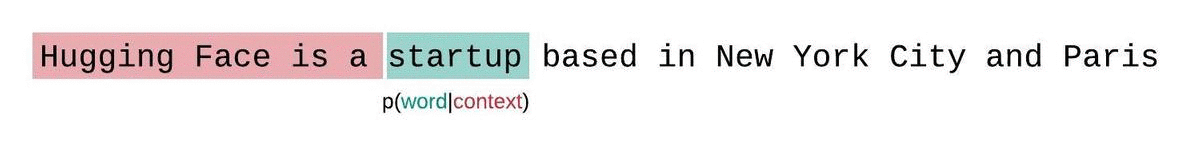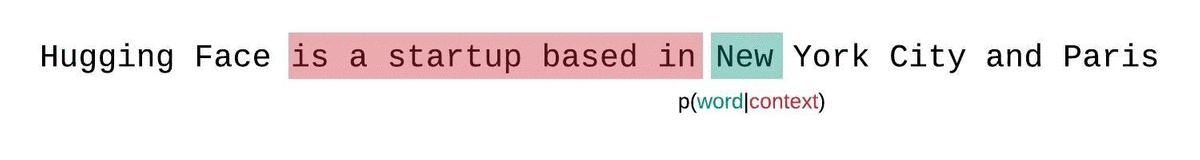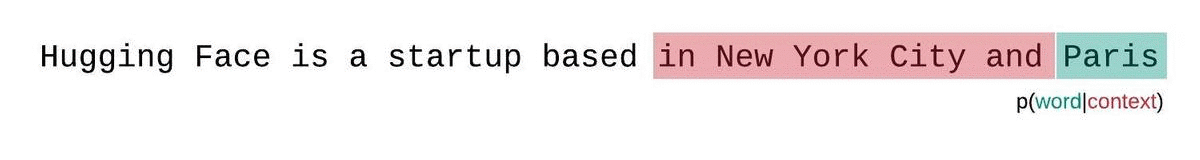
When working with longer output from GPT-2, the model simply can’t see it all at the same time. The best we can do is slide a window of 512 tokens (stride=512) and concat the results. See the documentation for details.
Perplexity is often reported as a single metric of an entire corpus. Here we scored the perplexity of each individual output for the sake of comparison.
Distance-to-Human (DTH)
Limited to Total Repetitions and Perplexity as defined above, we will attempt to define one final metric: Distance-to-Human.
Here is a sample output (text prompt in blue):
“Forty-two!” yelled Loonquawl. “Is that all you’ve got?”
“F[word], I dont care anymore. Turns out my boyz is sucka. They like their Internet under-hosed and back up using webmd!”
Loonquawl had imitated Clack like a crazy person. Instead of your average twink hero, he was playing a professor with O’Play as a teacher. Good for him. […]
The above prompt was inspired by this passage, written by a human:
“Forty-two!” yelled Loonquawl. “Is that all you’ve got to show for seven and a half million years’ work?”
“I checked it very thoroughly,” said the computer, “and that quite definitely is the answer. I think the problem, to be quite honest with you, is that you’ve never actually known what the question is.” […]
For each prompt based on a human text, we generated 10 texts with each of the 5 methods described above, 50 generated texts per prompt. We calculated individual Total Repetitions and Perplexity scores for all generated texts, and for the corresponding human text. This allows us to visualize this distance in two-dimensional space:
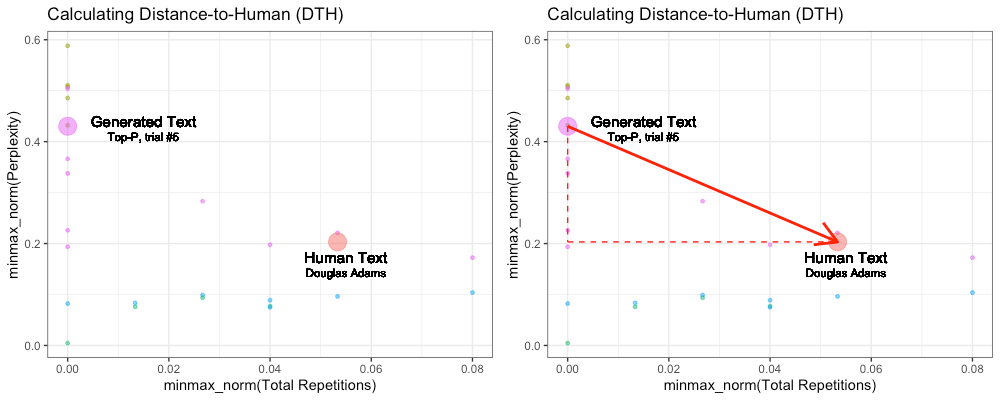
We found radical differences in scores depending on the prompt provided. Therefore, we calculated DTH based on scores min/max normalized on all texts belonging to each specific prompt. Above are all texts generated in response to the Douglas Adams prompt.
Our goal with this model is to generate a new, creative text output. Does comparing that output to the human original make sense? Aside from sharing the same prompt, they are two completely different passages. Is it reasonable to assume that the same prompt should yield output with similar levels of perplexity and repetition, whether written by human or machine?
Here we come face-to-face with our biggest challenge in evaluating these generated texts. What should we compare them to?
Other NLP Metrics
There exist countless other metrics for NLP, but many of them share the same limitation: we need something to compare our generated texts to.
BLEU and ROUGE
BLEU and ROUGE are used to compare computer-written summaries or translations to human-written summaries or translations. They rely on comparison of ngrams between the two.
Put simply, BLEU measures precision; how many ngrams in the output were included in the labels (human text)? ROUGE measures recall; how many ngrams in the labels (human text) were included in the output?
Here we have asked the machine to write its own output, not summarize or translate anything specific. BLEU and ROUGE are not useful here.
Translation Edit Rate (TER)
Simply stated, the Translation Edit Rate (TER) measures the number of actions needed to turn a computer output back into the human label it was based on. Again, not helpful here, since there is nothing to compare to.
Latent Semantic Analysis (LSA)
Latent Semantic Analysis (LSA) attempts to vectorize the context and meaning of a text, so that it can be compared to another; similar to the word embeddings discussed above. This is an interesting, more flexible approach. In many cases, we want to check whether or not the machine “got the gist of it“. We don’t really care if it uses the same specific words, or order, or quantity, so long as the same key concepts come through.
Sadly, any metric based on a direct comparison of a generated text, to another text, is useless to us here. We are asking for creative writing. The meaning of any given output may vary wildly from another.
In this case, that’s a feature, not a bug.
Examples of Human Text
To get a more intuitive sense of what Total Repetitions and Perplexity scores actually mean, let us consider some different examples of human text.
Douglas Adams
It seems appropriate to start with this passage from Douglas Adams’ timeless classic The Hitchhiker’s Guide to the Galaxy:
“Forty-two!” yelled Loonquawl. “Is that all you’ve got to show for seven and a half million years’ work?”
“I checked it very thoroughly,” said the computer, “and that quite definitely is the answer. I think the problem, to be quite honest with you, is that you’ve never actually known what the question is.”
“But it was the Great Question! The Ultimate Question of Life, the Universe and Everything!” howled Loonquawl.
“Yes,” said Deep Thought with the air of one who suffers fools gladly, “but what actually is it?”
A slow stupefied silence crept over the men as they stared at the computer and then at each other.
“Well, you know, it’s just Everything… Everything…” offered Phouchg weakly.
“Exactly!” said Deep Thought. “So once you do know what the question actually is, you’ll know what the answer means.”
Dr. Seuss
From the Dr. Seuss classic The Lorax:
At the far end of town where the Grickle-grass grows and the wind smells slow-and-sour when it blows and no birds ever sing excepting old crows… is the Street of the Lifted Lorax.
And deep in the Grickle-grass, some people say, if you look deep enough you can still see, today, where the Lorax once stood just as long as it could before somebody lifted the Lorax away.
What was the Lorax? And why was it there? And why was it lifted and taken somewhere from the far end of town where the Grickle-grass grows? The old Once-ler still lives here.
Ask him, he knows.
You won’t see the Once-ler. Don’t knock at his door. He stays in his Lerkim on top of his store. He stays in his Lerkim, cold under the floor, where he makes his own clothes out of miff-muffered moof. And on special dank midnights in August, he peeks out of the shutters and sometimes he speaks and tells how the Lorax was lifted away. He’ll tell you, perhaps… if you’re willing to pay.
Tale of Two Cities
From the Dickensian classic:
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair, we had everything before us, we had nothing before us, we were all going direct to Heaven, we were all going direct the other way—in short, the period was so far like the present period, that some of its noisiest authorities insisted on its being received, for good or for evil, in the superlative degree of comparison only.
The Bible
From the King James Bible:
In the beginning God created the heaven and the earth.
And the earth was without form, and void; and darkness was upon the face of the deep. And the Spirit of God moved upon the face of the waters.
And God said, Let there be light: and there was light.
And God saw the light, that it was good: and God divided the light from the darkness.
And God called the light Day, and the darkness he called Night. And the evening and the morning were the first day.
And God said, Let there be a firmament in the midst of the waters, and let it divide the waters from the waters.
And God made the firmament, and divided the waters which were under the firmament from the waters which were above the firmament: and it was so.
And God called the firmament Heaven. And the evening and the morning were the second day.
And God said, Let the waters under the heaven be gathered together unto one place, and let the dry land appear: and it was so.
CNN
Taken from CNN.com Feb 4, 2022: Beijing Winter Olympics: Norway off to golden start as China claims first gold
Having arrived in China as the most successful country in Winter Olympics history, Norway was quickly into the groove on day one of Beijing 2022 as the Nordic country got off to a golden start on Saturday.
Norway claimed two gold medals on Saturday to take its all-time gold tally to 134 — that’s 29 more than the United States, which sits in second on 105.
Therese Johaug won the first gold of Beijing 2022 with a dominant victory in the 15-kilometer cross-country skiing race in the women’s skiathlon, the Norwegian cruising to her first individual Olympic title in 44 minutes and 13.7 seconds.
The 33 year old is competing in her third Games, but missed PyeongChang 2018 due to a positive drug test in 2016.
Taken at random from Reddit.com Feb 4, 2022: comment left in Relationship Advice post by Annie_Hp
Yes! This! I wanted to say that the thing I wanted more than anything (other than snacks, haha) when I was pregnant was connection and understanding from my husband. He was great about it too. Listen to her concerns, any that she brings up, take them seriously, don’t deride her or dismiss her. Get curious about what she’s curious about- if she’s reading a pregnancy and parenting book, buy yourself a copy and read it with her. If she wants to talk about plans, participate and plan with her. Let her take the lead on deciding what’s important right now- don’t push her to think the way you’re thinking. The first trimester is so exhausting, I’ve never been more tired in my life. It leaves no energy for anything- every little thing takes so much energy and it barely leaves you with enough energy to even think. So if you can ease the mental and emotional burden like the above poster said, you’ll be doing her a huge favor and you two will grow closer in the process.
Visualized
Here we visualize the above scores in two-dimensional space:
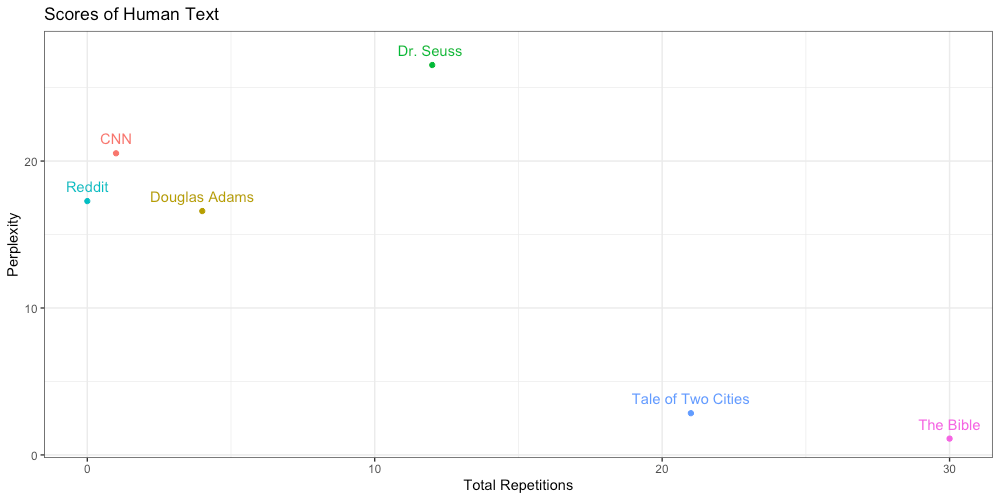
The first thing to notice is that some amount of repetition is expected. The only human text with absolutely no repetition was the comment from Reddit. Some authors use a lot of repetition as a stylistic choice, as we see in “Tale of Two Cities” and “The Bible”. It’s not quite as simple as repetition = bad.
In terms of perplexity, we see Dr. Suess is the most perplexing, likely due to his habit of inventing his own words (unknown tokens to our model). We find “Tale of Two Cities” and “The Bible” are not only the most repetitive, but also the least perplexing. This led to an interesting observation:
Prompts Matter
The choice of prompt has a significant effect on output, regardless of the model used. Consider this sample output (text prompt in blue):
In the beginning God created the heaven and the earth. And the earth was without form, and void; and darkness was upon the face of the deep. And the Spirit of God moved upon the face of the waters.[…]
Compare to this sample output (text prompt in blue):
In the beginning God created the heaven and the earth. And the earth was without form, and void; and darkness was upon the face of the deep. And the Spirit of God moved upon the face of the waters. […]
Compare to this sample output (text prompt in blue):
In the beginning God created the heaven and the earth. And the earth was without form, and void; and darkness was upon the face of the deep. And the Spirit of God moved upon the face of the waters. […]
As we see above, regardless of method, the prompt “In the beginning God created the heaven and the earth.” keeps generating the same biblical scripture again and again.
The same happens with “Tale of Two Cities” (text prompt in blue):
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair […]
Compare to (text prompt in blue):
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair […]
It appears that the prompts “In the beginning God created the heaven and the earth.” and “It was the best of times, it was the worst of times, it was” are so iconic, repeated so often in the text GPT-2 was trained on, that the likelihood of these sequences completely overwhelm those of the competitors, regardless of which generation method we use.
Crash Course Review
We’ve covered a lot of material here. If you’ve been paying attention, you should now be able to answer the following questions:
- What is the GPT-2 model and where did it come from?
- How do we use Google colab to generate text from our web browser?
- What is the difference between these generation methods?
- What do these generation methods have in common?
- Beam Search
- Sampling
- Temperature
- Top-K
- Top-P
- What are some objective measures of generated text?
- What do these measures mean?
- Repetition
- Perplexity
- Distance-to-Human (DTH)
- BLEU
- ROUGE
- Translation Edit Rate (TER)
- Latent Semantic Analysis (LSA)
- Are all prompts equally good for generating text?
Bonus question:
- If output from a GPT model passes the Turing test, could said model be considered a legitimate “machine that can think”? Why or why not?
Want more content like this? Please subscribe and share below: